
User Tools
Table of Contents
CUDA
Compute Unified Device Architecture
CUDA_HOME一般就是/usr/local/cuda(指向CUDA Toolkit的安装目录,可以使用可替换命令管理多个版本)
学习资料:
- CUDA 编程入门(HPC Wiki) https://hpcwiki.io/gpu/cuda/
- CUDA Tutorial https://cuda-tutorial.readthedocs.io/
- xiaoxiong(关于CUDA的博客,很有帮助) https://littlebearsama.github.io/tags/CUDA/
- GPU高性能编程CUDA实战
- [官方中文文档]CUDA C++ 编程指南 https://docs.nvda.net.cn/cuda/cuda-c-programming-guide/index.html
- [官方中文PDF]NVIDIA CUDA 编程指南 https://www.nvidia.cn/docs/IO/51635/NVIDIA_CUDA_Programming_Guide_1.1_chs.pdf
- [官方]CUDA Toolkit Documentation https://docs.nvidia.com/cuda/index.html
- [官方]CUDA Runtime API https://docs.nvidia.com/cuda/cuda-runtime-api/
查询列表:
- 硬件的计算能力列表 https://developer.nvidia.com/cuda-gpus
基础知识
NVIDIA GPU
- GT:Graphics Technology
- GTX:Giga Texel Shader eXtreme
- RTX:引入了RT Core、Tensor Core
关于硬件的理解(细节处可能有错误):原本GPU是为了绘制图形所设计的硬件,主要工作是计算vert和frag等着色器,主要也是进行向量矩阵等运算,后来NV把这部分计算硬件设计成了通用的,也就是CUDA中的SM/CUDA Core(这里补充一下,SM=流多处理器,SP=流处理器=CUDA Core,1个SM包含多个SP),原本的功能不变,同时也可以运行自定义的通用计算代码了。后来,因为深度学习的需要,NV加了Tensor Core,因为实时光线追踪的需要,NV加了RT Core,这两种都是单独的新硬件,(目前)都是进行其对应类型的计算,(应该)还不能做通用类型的计算,所以不在CUDA的范围内。【AI:RT Cores 和 Tensor Cores(区别于CUDA Cores) 不能用于传统意义上的 CUDA 通用计算,它们针对的是非常专用的任务,因此你不能用它们来替代 CUDA Cores 来做通用浮点、整型计算或控制流程】
新显卡不一定支持旧版的CUDA,硬件确定之后,可以使用的CUDA版本也就有了一个范围。比如 RTX 4060 需要使用 CUDA 11.8 或更高版本。那么新版的CUDA一定支持旧显卡吗?[待确认]
总结:硬件和CUDA版本的兼容性要好好确认。
微架构和硬件有关,微架构决定Compute Capability(计算能力),计算能力写为8.0(不是具体这个数字,为了展示格式举个例子而已),有时候也叫80,sm_80。根据微架构(or计算能力),安装CUDA的时候要选择合适的版本,同样,根据CUDA的版本,安装驱动的时候,也要选择合适的驱动版本(一个驱动有最高支持的cuda版本,一个cuda有最低需要的驱动版本)
NV官方提供的API or samples,有些也需要对应的计算能力范围,比如sm50 - sm90
| 型号&备注 | 微架构(microarchitecture) | 计算能力(Compute Capability) | CUDA Version | cores (SM) | max_threads (block) | max_threads (SM) | max_blocks (SM) |
|---|---|---|---|---|---|---|---|
| Tesla (2006) | 1.0 | 512 | |||||
| Fermi (2010) | 2.0 | 32 | 1024 | ||||
| Kepler (2012) | 3.0 | 192 | 1024 | ||||
| Maxwell (2014) | 5.0 | 128 | 1024 | ||||
| 代表产品:GTX 1080 Ti。早期:基本上是 一个架构覆盖所有市场 | Pascal (2016) | 6.0 | 64 / 128 | 1024 | |||
| 初现分化:V100首次引入了Tensor Cores。不是面向游戏应用,所以没有GTX系列出现 | Volta (2017) | 7.0 | 64 | 1024 | |||
| 面向游戏应用,对应GeForce 16/20系列 | Turing (2018) | 7.5 | 64 | 1024 | |||
| GeForce 30系列 & A100。游戏显卡和专业显卡使用的同一个架构 | Ampere (2020) | 8.0 | 128 | 1024 | 2048 | ||
| 正式“路线分离”:Ada只对应游戏显卡,GeForce 40系列,比如RTX 4080 Ti | Ada Lovelace (2022) | ||||||
| Hopper只对应专业显卡:H100 / H200 | Hopper (2022) | ||||||
| GeForce 50系列/B100 & B200:又合并了?品牌统一但架构分化 | Blackwell (2024) | ||||||
| Rubin (2026) | |||||||
| Feynman (2028) |
编程模型
Grid(对应一个global函数,是逻辑概念) > SM(Stream Multiprocessor,SM是硬件概念。有时候也被叫做“GPU大核”)>= Block(1个SM上,运行1个或者多个Block,取决于Block的资源需求,所以不用担心,一个Block的Thread分配少了,导致SM的资源被浪费;SM资源可分,但是1个Block不能被分开在不同的SM上运行) > Thread Warp(线程束,参考内存管理的部分) > Thread
关于Nvidia GPU硬件架构和对应的CUDA编程模型:
CUDA是在Nvidia的GPU上编写并行程序的模型,在CUDA模型中,Nvidia的GPU由多个SM流式多处理器组成,SM包括了多个CUDA核心,CUDA核心是用于计算的最小单位,每一个核心上运行一个线程。
在启动并行程序的时候,我们会产生一个Grid,Grid包括多个SM的计算任务,但是我们不需要考虑运行的硬件到底有几个SM,GPU驱动会自动分配SM任务,如下图
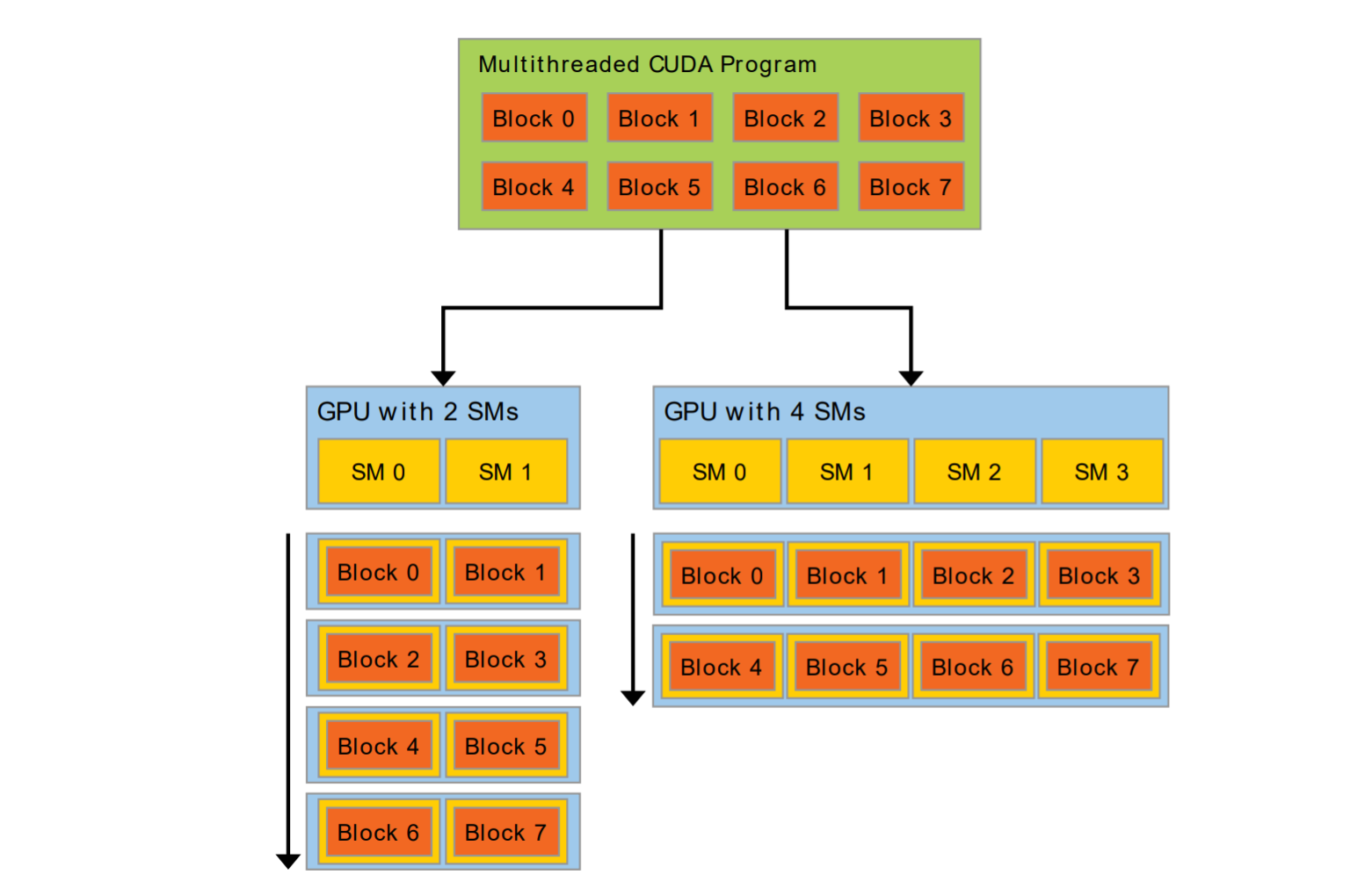
程序是自动并行运算的,在编程层面,我们创建的概念是一个Grid,一个Grid包含多个Blocks(线程块,可指定数量),每一个Block包含多个Threads(计算的最小单位,单个线程,可指定数量),所有的Threads一起运行,如下图
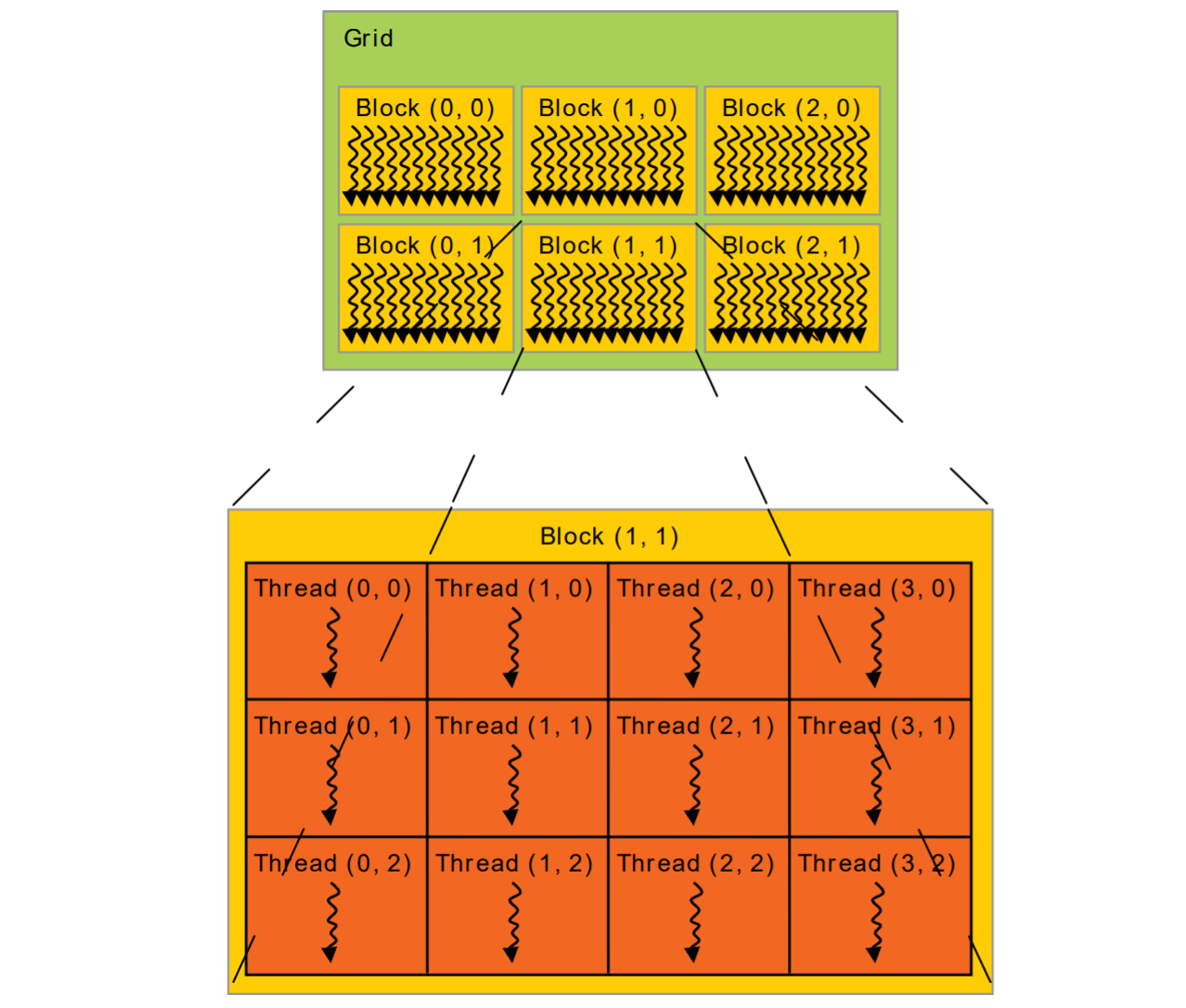
那么我们就可以得到硬件和编程概念上的联系了:
- GPU设备:对应Grid,Grid可能比较小,分配到部分GPU的资源,可能比较大,分配到全部GPU的资源并排队(串行)执行,分配的结果与计算任务的大小和GPU的计算资源相关,由驱动自动决策,不需要我们考虑。
- SM流式多处理器:对应Block,一个SM承担一个Block的计算任务。
- CUDA计算核心:对应Thread,一个计算核心运行一个Thread,多个计算核心同时运行实现并行运算。
注意:无论是Block还是Thread,并行执行,执行的先后顺序都是不确定的,有依赖关系的计算任务不能并行!
3种函数
host指主机端(CPU),device指设备端(GPU),3种函数类型如下:
- __host__: 这类函数与正常的函数没有区别。其只能被 host 上执行的函数(__host__)调用,并在 host 上执行。使用修饰符__host__修饰,在CPU端调用,也在CPU端执行,也就是最普通的函数,不加修饰符默认就被看作是Host函数
- __global__: 这类函数可以被任何函数调用,并在 device 上执行。使用修饰符__global__修饰,在CPU端调用,在GPU端运行,是CPU给GPU下达命令、沟通交互的关键(CUDA Kernel,也就是核函数)
- __device__: 这类函数只能被 device 上执行的函数(__device__ 或 __global__)调用,并在 device 上执行。使用修饰符__device__修饰,只能在GPU端调用(也就是在Global函数或者Device函数中调用),也是在GPU端运行
关于调用的方式:
- 在启动 CUDA Kernel 时,<<<x,y>>> 中的第一个数字是每一个 Grid 中的 Block 数量,第二个数字是每一个 Block 中的 Thread 数量(每一个 Block 中含有的 Thread 数量是相等的)。那么,Grid的数量是?Grid应该只有1个,1个global函数对应1个Grid
- Host函数和Device函数就是正常的调用方式,但是Global函数涉及到了CPU和GPU的交互,在调用的时候就是启动了一个并行计算的任务,所以需要指定GPU计算需要的尺寸,使用<<<,>>>(3层的尖括号)来指定Block的数量、每个Block中Thread的数量
- 调用Global函数是异步的,也就是调用Global函数是不会阻塞主进程的,GPU的计算在后台并行进行,所以也需要一些同步手段
指定Grid和Block的维度:
Gird是包含N个Block的集合,Block是包含N个Thread的集合,这些集合可以有维度,比如Block包含N个Thread,这N个Thread可以是(N),也可以是(2,N>>1),也可以是(2,2,N>>2),只要Thread的总数在范围之内就可以(每个Block内最多包含的Thread数量是一定的,这个数字是由硬件决定的)。另外,每个维度的范围也有一个上限,比如,通过 cudaDeviceProp 结构体中的 maxThreadsDim[] 数组,可以查询每个 Block 在各个维度中支持的最大线程数。
维度最多有3个,以Block举例来说,在只有1维的时候,每个Thread通过ID.x区分,2维的时候通过ID.x和ID.y区分。正确的选择维度可以提升性能。在调用global函数的时候,<<<x,y>>>内的x和y不一定必须是标量,也可以是CUDA提供的向量类型,比如dim3就是CUDA提供的3维向量(x,y,z),通过dim3的形式就可以指定Grid和Block的维度【dim3 blockSize(16, 16); 另外,没有 dim2 这种东西】。
梳理总结
- 核函数(kernel)
- 设备属性(和状态)
- 编译器指令(宏)
- CUDA Stream(流,并行之上的串行结构)
- 多设备(多个GPU,单一节点)
- libcudacxx (CUDA Standard C++ Library)
- 平台专属问题(Linux / WSL / Windows)
- 编译流程(nvcc 和 llvm)
- MIG (Multi-Instance GPU)
- NVIDIA Management Library (NVML)
- GPUDirect Storage https://docs.nvidia.com/gpudirect-storage/
随便看看
- 这是史上最快GPU!我们测了四张H100!价值120万元! https://www.youtube.com/watch?v=-nb_DZAH-TM
- RTX 50系显卡来了!NV有哪些干货? https://www.youtube.com/watch?v=kX0u_liufRg
- A卡崛起之路:重现当年AN显卡巅峰对决! https://www.youtube.com/watch?v=BlI9PVQA8ZA
- N卡是如何崛起的?20年前的PC和游戏(下) https://www.youtube.com/watch?v=JsVfKeJKJu0
- 我们用三张4090点亮了五个8K电视! https://www.youtube.com/watch?v=rQ9flVXRpLg
- 【硬核科普】从零开始认识显卡 https://www.youtube.com/watch?v=vtR7cgYATdk
并行框架比较[AI]
因为最常用的并行框架是CUDA,所以就把「不同框架之间的对比」放在这里了
CUDA、OpenCL、OpenACC、OpenMP
| 特性 / 模型 | OpenACC | CUDA | OpenCL | OpenMP |
| 编程范式 | 指令式(directive-based) | 编程语言扩展 | 底层 API(C 语言风格) | 指令式(directive-based) |
| 控制粒度 | 中(依赖编译器优化) | 高(完全手动控制) | 高(细粒度控制所有计算和内存) | 中(适合 CPU 并行) |
| 性能潜力 | 中高(取决于编译器优化质量) | 最高(最大化利用 GPU 能力) | 高(跨平台优化空间大) | 中(新版本也支持 GPU) |
| 可移植性 | 高(面向异构平台) | 低(仅支持 NVIDIA GPU) | 最高(支持几乎所有主流硬件) | 中高(5.0起支持 GPU) |
| 目标硬件 | GPU、CPU(主要是 GPU) | NVIDIA GPU | 多种平台(CPU、GPU、FPGA、DSP) | 多核 CPU(5.0+ 可用于 GPU) |
| 学习曲线 | 平缓 | 陡峭 | 陡峭(尤其是平台/设备管理) | 最简单 |
| 生态支持 | PGI/NVIDIA 编译器最优 | NVIDIA 工具链完善 | 跨平台支持广泛,工具多样 | GCC/Clang 强力支持 |
| 典型使用场景 | 科学计算、大型仿真 | 高性能 GPU 编程 | 跨平台通用并行应用、嵌入式系统 | 多核 CPU 并行(工程/科研计算) |
Misc
GPGPU 是 “General-Purpose computing on Graphics Processing Units” 的缩写,中文叫做 通用GPU计算,意思是使用 图形处理单元(GPU)来进行非图形领域的通用计算任务。
Odt笔记(20221007)
Page Tools
