Table of Contents
CUDA内存管理
内存类型
CUDA 中大致有这几种内存:
- Global Memory:俗称显存,位于 GPU 核心外部,很大(比如 A100 有 80GB),但是带宽很有限(默认Malloc的的内存就是在这里吧)
- L2 Cache:位于 GPU 核心内部,是显存的缓存,程序不能直接使用(作为程序员,就不用惦记这一块了,明白原理就好)
- Register:寄存器,位于 GPU 核心内部,Thread 可以直接调用
- Shared memory:位于 GPU 核心内部,每个 Thread block 中的所有 Thread 共用同一块 Shared memory(因此,Shared memory 可以用来在同一个 Thread block 的不同 Thread 之间共享数据),并且带宽极高(因此,Shared memory 可以用来优化性能)。
申请、拷贝、回收(普通显存)
int32_t *a_gpu, *b_gpu, *c_gpu; cudaMalloc(&a_gpu, n * sizeof(int32_t)); cudaMalloc(&b_gpu, n * sizeof(int32_t)); cudaMalloc(&c_gpu, n * sizeof(int32_t)); cudaMemcpy(a_gpu, a, n * sizeof(int32_t), cudaMemcpyHostToDevice); cudaMemcpy(b_gpu, b, n * sizeof(int32_t), cudaMemcpyHostToDevice); cudaMemcpy(c, c_gpu, n * sizeof(int32_t), cudaMemcpyDeviceToHost); cudaFree(a_gpu); cudaFree(b_gpu); cudaFree(c_gpu);
获取内存信息
// Generated by AI #include <cuda_runtime.h> #include <stdio.h> int main() { size_t free_mem, total_mem; cudaError_t status = cudaMemGetInfo(&free_mem, &total_mem); if (status == cudaSuccess) { printf("Free memory: %zu bytes\n", free_mem); printf("Total memory: %zu bytes\n", total_mem); } else { printf("cudaMemGetInfo failed: %s\n", cudaGetErrorString(status)); } return 0; }
共享内存 Shared memory
每个SM内部都有一块内存,供SM内部的Threads使用,这块内存的访问速度比显存要快许多。同一个Block内部的Threads可以基于这块内存协作,不同Block的Threads基本很难通信
在访问共享内存的时候,要记得,Block内部的所有Threads访问的都是同一处内存
调用Kernel的时候分配(可分配动态大小)
// 调用的时候,指定需要的共享内存的大小 int shared_mem_size = BLOCK_SIZE * sizeof(float); sum_reduction<<<num_blocks, BLOCK_SIZE, shared_mem_size>>>(d_in, d_out, n); // 调用Kernel的时候,指定了的shared_mem_size大小的内存,会自动绑定到Kernel中第一个声明的extern __shared__ extern __shared__ float sdata[]; // 使用共享内存
在Kernel内部分配(只能分配固定大小)
int t_size = 16; __shared__ float t_data1[16]; __shared__ float t_data2[t_size]; // error: a variable length array cannot have static storage duration
Unified Memory
Unified Memory(统一内存)是 NVIDIA 在 CUDA 中引入的一种内存管理机制,让 CPU(主机)和 GPU(设备)可以共享一块内存区域
- 程序员不再需要显式地使用 cudaMemcpy() 把数据从 CPU 拷贝到 GPU。
- 系统在需要的时候自动将数据从主机内存迁移到 GPU 显存,或反过来。
- 它使得 GPU 可以访问超出显存大小的数据(只要主机内存够用)。
线程束 Thread Warp
什么是线程束(Warp)
虽然说每个CUDA核心运行一个线程,但是这是逻辑上的概念,每个线程看起来是独立的、互不关联,但实际在硬件上,线程被分了组,也就是线程束,它们之间有一定的关联,想要程序的执行效率更高,就要了解这些硬件上的特性。硬件和软件的不同如下图

流程
Block是逻辑概念,当一个Block被分配到一个SM上后,会分为多个线程束,线程束是硬件概念,现在的硬件一般是32个线程分为一个线程束,在一个线程束中,所有线程按照单指令多线程SIMT的方式执行,每一步执行相同的指令,但是处理的数据为私有的数据
线程束分化
不同的线程在同一个线程束中,它们执行相同的指令,那么如果流程中存在分支,而不同的线程进入了不同的分支,那么如何处理呢?前面提到同一个线程束中的线程执行相同的指令,现在不同的线程进入了不同的分支,执行的指令必然是不同的,产生了分化,这似乎是有矛盾的。GPU解决矛盾的办法就是等,每一个分支的指令,分配命令的调度器都会向所有线程发出命令,不应该执行这个分支的线程就要等,等到这个分支的所有线程都执行完毕,收到下一个命令,才可以继续。很明显这会造成性能的下降,分支越多,分化越严重,就越像串行的程序(一些线程等其他的线程结束才能继续),性能损耗也就越严重。执行过程如下图
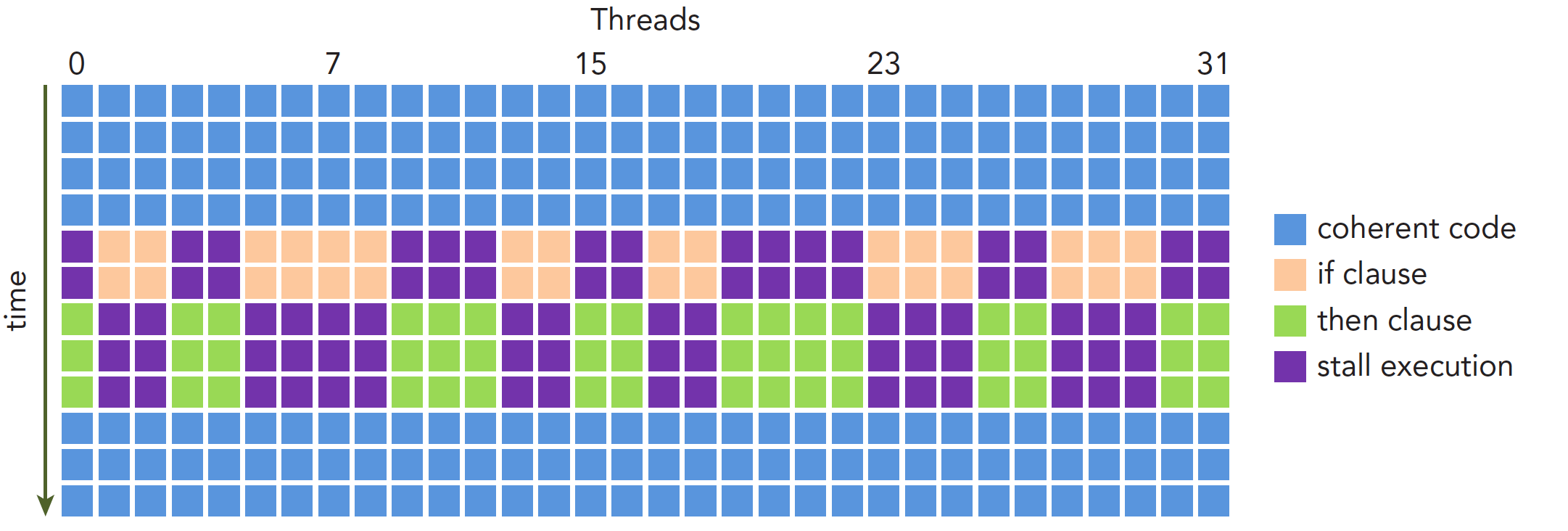
避免性能下降的方法自然就是减少分化,我们要尽量让数据有规律,相同线程束内部的线程尽量执行相同的分支,要注意的是,如果线程束内所有的线程在某一个分支点都选择了相同的走向,那么这样的情况是不会造成等待的
常量内存
也就是GPU端的常量,使用__constant__进行修饰,优点是(在使用正确的情况下)可以提升性能
常量内存内的数据,并不是声明之后就永远不可改变,而是在核函数运行期间不可以改变
https://github.com/GZhonghui/cuda_samples/tree/master/04_constant
参考资料:
- 使用cuda常量内存进行性能优化: https://www.cnblogs.com/wangtianning1223/p/17266234.html
// Step 1 __constant__ float gpu_fib[maxn]; // 声明GPU常量 // Step 2 // 将常量数据从Host拷贝到Device // GPU常量不需要显式Malloc和Free cudaMemcpyToSymbol(gpu_fib, fib, sizeof(float) * maxn); // Step 3 if(threadIdx.x < n) { res[threadIdx.x] = gpu_fib[threadIdx.x] + 1; // (在Kernel内部)访问GPU常量 }
纹理内存
可以参考GPU高性能编程CUDA实战 C7
纹理内存也是一种常量内存
不可分页内存(锁页)
unpin_memory / pageable(普通)内存 VS pinned(锁页)内存
区别很好理解(是否可以换出到磁盘,虚拟地址还是物理地址),但是注意:这是【Host Memory】的区别,GPU内存是没有这个区分的,GPU应该也无法访问磁盘(GPUDirect可以)
需要注意的是:在GPU之间传递数据的时候,如果支持P2P则无须经过Host,但是如果需要经过Host的话,好像需要分配pinned memory?而pinned memory不能分配太多(除了硬件资源的限制,系统也会限制)
不可分页内存(AI生成)
CUDA(Compute Unified Device Architecture)是NVIDIA开发的一套并行计算平台和编程模型,它允许开发者利用NVIDIA GPU强大的计算能力来加速应用程序。在CUDA中,内存管理是一个重要的部分,尤其是如何高效地申请和使用不可分页(pinned)内存。
不可分页内存的优势
在CUDA编程中,数据通常需要在主机(CPU)内存和设备(GPU)内存之间传输。默认情况下,主机内存是可分页的,这意味着操作系统可以将不常用的数据页交换到磁盘,从而为新的内存请求腾出空间。然而,这种可分页内存的数据传输效率较低,因为每次传输到设备之前,操作系统需确保数据页在物理内存中是连续的,这一过程称为页锁定。
使用不可分页内存,可以避免页锁定的开销,因为这部分内存由操作系统锁定在物理内存中,不会被交换到磁盘,其数据传输到GPU的速度通常比可分页内存更快。
如何申请不可分页内存
在CUDA中,申请不可分页内存可以使用以下API函数:
cudaMallocHost(void **ptr, size_t size);
ptr: 指向主机端指针的指针,该指针用于访问申请的内存。size: 需要申请的内存大小,以字节为单位。
这个函数申请的内存区域在物理内存中是连续的,并且被锁定,因此其地址不会发生变化,适合高速传输。
示例代码
下面是一个简单的示例,展示如何在CUDA中申请和使用不可分页内存:
#include <cuda_runtime.h> #include <iostream> int main() { float *h_A; // 主机端的指针 float *d_A; // 设备端的指针 int num_elements = 1024; int size = num_elements * sizeof(float); // 申请不可分页内存 cudaMallocHost((void **)&h_A, size); // 申请设备内存 cudaMalloc((void **)&d_A, size); // 初始化数据 for(int i = 0; i < num_elements; i++) { h_A[i] = 0.5f; } // 将数据从主机传输到设备 cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice); // 释放内存 cudaFree(d_A); cudaFreeHost(h_A); return 0; }
使用注意事项
- 内存释放:使用
cudaFreeHost()来释放不可分页内存,不要使用标准的free()函数,因为它们涉及不同的内存池。 - 性能影响:虽然不可分页内存可以提升数据传输的性能,但过度使用可能会影响系统的总体性能,因为它减少了操作系统管理内存的灵活性。不可分页内存应当谨慎使用,仅在对传输性能有严格要求的场合下使用。
通过理解和合理使用不可分页内存,可以在CUDA应用程序中实现更优的数据传输性能。